
Term
Note
本文可能存在一些错误,请大家指教,我也会尽我所能去查阅一手资料,避免带来错误的认知。
Math
科学计数法
科学技术法是一种记数方法,表示 a 与10的n次幂相乘,避免超长数据影响我们的阅读。
比如 1 000 000 000 ,一眼看去 零太多,还需要逐一去数有几个零,如果用计算机来表示科学计数法表示就是 1E9。
计算机基础
进程:process,简单来说,一个正在运行的程序就是一个进程。
线程:CPU调度的最小颗粒,属于进程的一部分
协程:
ASCII 码
American Standard Code for Information Interchange,ASCII码是一种编码标准,包括128个字符,每个字符对应一个数值。
| 码值 | 字符 | 码值 | 字符 | 码值 | 字符 | 码值 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | \ | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
Unicode
Unicode 的介绍:Everyone in the world should be able to use their own language on phones and computers.
UTF-8
Universal Character Set/Unicode Transformation Format,
在UTF8编码中,英文只需要一个字节就可以表示,英文字符需要两个字节才能表示,但是中文需要三个字节才能表示。
原码
原码即原始二进制表示
如:1的二进制表示为1
2的二进制表示为01
3的二进制表示为11
4的二进制表示为100
以下为了方便看,我们使用都是用四位来表示
正负表示
在原码的基础上在最前面添加一位代表符号位,0代表正数,1代表负数
如:
0的二进制表示为0000
1的二进制表示为0001,-1的二进制表示为1001
2的二进制表示为0010,-2的二进制表示为1010
3的二进制表示为0011,-3的二进制表示为1011
4的二进制表示为0100,-4的二进制表示为1100
5的二进制表示为0101,-5的二进制表示为1101
6的二进制表示为0110,-6的二进制表示为1110
7的二进制表示为0111,-7的二进制表示为1111
带符号,四位可以表示多少的数字范围呢?
正数最大:0111 = 0111 = 0111 = 7
负数最大:1000 = -8(-8的补码为1000) ??(具体原因看下面 Note)
1 + -1 问题
我们告诉计算机用原码去计算 1 + -1,会是什么效果呢?
1 + (-1) = 0001 + 1001 = 1010 = -2 ??此时,计算机用原码计算结果是不正确的
反码
正数的反码为其本身
复数的反码是在其原码的基础上,符号位不变,其余位取反
如:
1的反码表示为0001,-1的反码表示为1110
2的反码表示为0010,-2的反码表示为1101
3的反码表示为0011,-3的反码表示为1100
4的反码表示为0100,-4的反码表示为1011
1 + -1 问题
此时,如果我们告诉计算机用反码去计算 1 + -1,会是什么效果呢?
1 + (-1) = 0001 + 1110 = 1111 = 1000 = -0 ??此时,计算机用反码计算结果是正确还是不正确的呢?
但从数值来看是正确的,为0,但是又因为其符号位是负数,我们知道,0既不是正数也不是负数,只能说结果不合理。
补码
正数的补码为其本身
负数的补码是在其原码的基础上,符号位不变,其余位取反,最后+1,即在其反码的的基础上+1
如:
1的补码表示为0001,-1的补码表示为1111
2的补码表示为0010,-2的补码表示为1110
3的补码表示为0011,-3的补码表示为1101
4的补码表示为0100,-4的补码表示为1100
1 + -1 问题
1 + (-1) = 0001 + 1111 = 10000 = 16 - 1 = 15 = 01111 = 00000 = 0
常说的数据范围中,大多是使用补码来表示的,比如c
在c语言中,4bit 能表示的范围就是:-8(1000) 到 7(0111)
Note
我们在计算一个数据在计算机中实际的二进制编码时需要用如下规律
整数 <-> 原码 <-> 反码 <-> 补码 <-> 计算机
单位
bit
上面我们计算原码、反码、补码的时候,每一个0或1都代表1bit,也就是1位。
B
在计算机中,我们经常看到下载的速度。
那么1B等于多少呢?
1 B = 8 bit
1字节 = 1B
1英文字符 = 2字节
1中文字符 = 3字节
计算机语言
计算机语言按其与硬件接近的程度可以分为低级语言和高级语言。
低级语言
低级语言包括机器语言(machine language)和汇编语言(assembly language)。
在具体了解机器语言和汇编语言之前,我建议先了解一下如下定义:
指令
instructions,能够被计算机硬件直接执行。
光说可能还是有点抽象,举个例子吧,如果我想给计算机发送一个ADD的操作指令,我该如何用机器语言实现呢?
答案是:我暂时也不知道,但是可以参考x86指令集参考,其中的Opcode我理解就是机器语言的体现。
这里关于汇编语言由于本人了解的很少,且没有太多的精力在这方面,所以只是浅尝辄止,大致对其有了认知。
寄存器
直接说我的理解:寄存器是一种内存,直接建立在CPU里的内存,读取速度比L1 Cache还要快,CPU会优先读取寄存器。
内存模型
机器语言
即计算机能懂的语言,我们应该都知道,计算机本身只能识别二进制代码,即0、1,当然,直接食用二进制进行编程在我看来是基本不可能的事情(虽然在计算机诞生之初,那些伟大的人们就是直接使用二进制、十六进制直接进行的编程),况且机器语言就是使用二进制编程的话,那不如叫二进制语言好了。想象一下,如果我们现在的编程环境是用二进制编程,那么一个Java关键字翻译成二进制将是一个很费时费力的过程,更不要说写出成千上万行的代码了。不仅如此,我们在排查问题的时候,面对一堆的...01101010...,应该会崩溃的吧,所以,人们在二进制基础上创建了指令,我们都知道,二进制代码按照ASCII码表可以翻译成对应的符号,所以能够被计算机硬件识别的二进制代码构成了指令。由指令构成的集合被称为指令集,就是机器语言,同样也是指令集架构(如x86)的重要组成部分。
汇编语言
由于机器语言记忆困难,编写程序不便,阅读困难,修改和调试费力等原因,喜欢偷懒的人们发明了汇编语言,在机器语言的基础上,人们为了方便记忆,将指令代码与指令的功能的英文缩写绑定,以便使用相关功能的英文缩写就能达到使用机器语言的效果。
所以简单来说,汇编语言就是二进制指令的功能文本缩写。
高级语言
计算机网络
HUB:集线器,物理层设备,需要用到协议
SW:switch,交换机,数据链路层设备
Router:路由器,也叫网关,连接两个大型局域网,网络层设备
- WAN:Wide Area Network,广域网,IPv4形势192.168.1.51,代表局域网对外的IP地址
- LAN:Local Area Network,局域网,IPv4形势192.168.0.1/24,代表一个局域网
- ARP:ARP协议,局域网内通信协议
RPC:(remote procedure call)远程服务调用 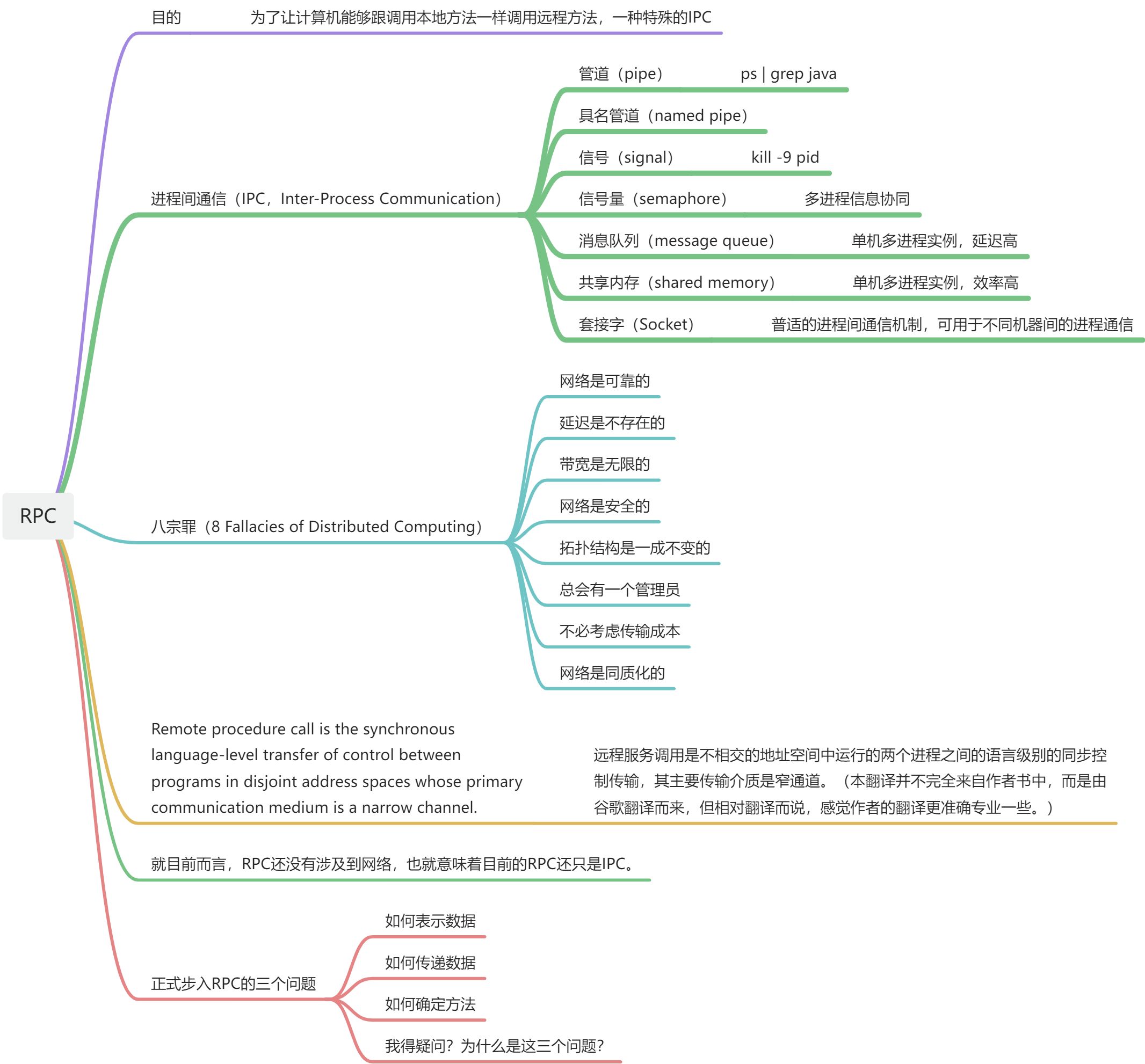
REST:Representational State Transfer,表征状态转移
Linux
SELinux:Security-Enhanced Linux 是一种强制访问控制(MAC)安全模块,旨在提高 Linux 操作系统的安全性
内核
参考
- 计算机基础 by tsinghua